
Avec la crise du coronavirus Covid-19, tout le monde scrute avec inquiétude et espoir les projections concernant l’évolution de l’épidémie. Trois experts nous éclairent sur la science derrière ces modèles et les précautions à prendre concernant leurs interprétations.
Avec
l’entrée en vigueur du confinement, l’épidémie de Covid-19 s’impose à toute la
population française et au-delà. Impossible alors de ne pas tenter de savoir
combien de temps la crise va durer et au prix de combien de victimes.
Différents modèles et prédictions existent, mais comment aborder ces outils
scientifiques et médicaux qui ne sont pas conçus, à la base, pour éclairer le
grand public ? Comment sont-ils construits ?
« Les
modèles d’épidémies sont généralement de deux types : agrégés, à l’échelle
des populations, ou distribués, à l’échelle des individus », explique
Éric Daudé, géographe et directeur de recherches au laboratoire Identité
et différenciation de l’espace, de l’environnement et des sociétés1. Ils vont
ainsi du peu précis, mais pratique aux grandes échelles, au très détaillé qui
ne décrit qu’un contexte très spécifique. Les modèles développés dans le cadre
du Covid-19 entrent dans la première catégorie, où des équations
différentielles décrivent l’évolution de l’état de quatre genres de population :
Saine, Exposée, Infectée et Remise (Seir).
Les volumes
de ces groupes changent en fonction de la dangerosité du virus et des moyens
mis en œuvre pour lutter contre le fléau. La contamination joue d’abord sur
trois critères : le nombre de contacts entre individus sains et infectés,
la facilité qu’a le pathogène à se transmettre lors de ces contacts et la durée
pendant laquelle les patients sont infectieux. Ce modèle de base peut être
amélioré selon les scénarios envisagés, en intégrant les mouvements de population,
les expositions différenciées, les tranches d’âge… « Ces modèles
macroscopiques sont assez parcimonieux, c’est-à-dire qu’ils utilisent peu de
paramètres, calibrés au fur et à mesure que l’on connaît mieux la maladie »,
précise Éric Daudé. Ils reposent en revanche des hypothèses très
simplifiées.
La seconde
catégorie, les modèles distribués, délaisse les modèles mathématiques de
groupes pour des approches informatiques qui décrivent des individus et des
comportements. Une méthode plus lourde, privilégiée lorsque les variations
environnementales et sociales sont déterminantes dans l’émergence et la
propagation de la maladie, ce qui est notamment le cas des maladies transmises
par des vecteurs, comme des moustiques ou des puces. Éric Daudé est en effet
spécialisé dans des pathologies telles que la dengue ou le chikungunya. Des
modèles qui permettent alors de guider les actions de désinsectisation à
l’échelle de quartiers, voire de rues, dans des villes vastes et complexes
comme Delhi ou Bangkok.
Des modèles face à l’inconnu
Si ces
modélisations sont utilisées depuis longtemps et ont fait leurs preuves, on
peut se demander ce qu’elles valent face à un virus très mal connu. « L’épidémiologie
a l’avantage d’obéir d’abord aux lois de la physique, insiste Samuel Alizon,
épidémiologiste et directeur de recherche au laboratoire Maladies infectieuses
et vecteurs : écologie, génétique, évolution et contrôle2. On
obtient les données à partir des courbes d’incidence hebdomadaires des nouveaux
cas et le suivi des contacts fournit l’intervalle sériel : le temps entre
l’apparition des symptômes chez une personne et leur survenue chez ceux qu’elle
a infectés. Un paramètre qui nécessite, en pleine épidémie, de retrouver des
couples infectant-infecté dans la population. » Le modèle est ensuite
calibré avec l’affinement des statistiques et connaissances existantes, par
exemple celles tirées de l’épidémie de SRAS de 2003, un coronavirus lui
aussi apparu en Chine.
Pour les
premiers stades des épidémies, les modèles stochastiques, c’est-à-dire basés
sur le hasard, sont privilégiés. En effet, un petit groupe de personnes
porteuses contamine les gens de manière très aléatoire. À partir d’un certain
moment, la loi des grands nombres prend le dessus : on peut alors
considérer que le taux de contamination est le même pour tout le monde. Les
chercheurs se tournent alors vers des modèles déterministes, qui permettent de
prévoir l’apparition des pics et de jauger les différentes stratégies de
contrôle. Typiquement, les modèles individu-centrés sont stochastiques, tandis
que ceux populationnels sont, en moyenne, plus déterministes.
Les modèles
aident aussi à mieux comprendre le virus. En comparant les prédictions aux
statistiques du terrain, les scientifiques repèrent les paramètres qui
expliquent les éventuelles différences. Ils en tirent des informations qui leur
échapperaient sinon et affinent leurs modèles.
Un manque de dépistage
« La plus
grosse difficulté n’est pas tant de découvrir quels sont les mécanismes de
propagation, mais de connaître les conditions initiales de l’épidémie, précise
Éric Daudé. Même sur des projections à moins de deux semaines, un écart de
quelques points de pourcentage sur la population que l’on pense contaminée
donne des résultats très différents. » Or la
faible ampleur du dépistage en France fait peser une grande incertitude sur la
question.
L’équipe de
Samuel Alizon se concentre depuis une semaine sur l’élaboration de nouveaux
modèles pour le Covid-19 dans l’Hexagone, où ces outils manquent, en
particulier comparé au Royaume-Uni. « Ils ont déjà des systèmes en
place où ils n’ont qu’à changer leurs paramètres, puis laisser tourner la
machine, avance le chercheur. Nous n’avons pas d’équivalent et nous
devons en plus mesurer les effets du confinement. Ce serait d’ailleurs plus
facile si une plus large partie de la population était testée, au lieu de
seulement constater les cas les plus sévères. » Des outils issus de
publications particulièrement fondamentales sont cependant disponibles pour
améliorer les simulations.
Jean-Stéphane Dhersin,
professeur à l’université Sorbonne Paris Nord, membre du Laboratoire analyse,
géométrie et applications3 et
directeur adjoint scientifique de l’Institut national des sciences
mathématiques et de leurs interactions du CNRS, est ainsi d’abord spécialisé
dans des modèles mathématiques très théoriques. Avec l’augmentation de la
puissance de calcul et du traitement des données, ses travaux ont pu être
appliqués. Jean-Stéphane Dhersin s’est alors progressivement intéressé aux
problèmes de génétique des populations puis aux épidémies.
L’importance du R zéro
Le
mathématicien a simplifié certains modèles, démontrant que certains outils accessibles
offraient des résultats suffisamment proches des modèles les plus lourds et
complexes. Ainsi, le processus de Bienaymé-Galton-Watson, conçu à l’origine
pour surveiller… la survivance des noms de la noblesse britannique, est un
modèle stochastique utilisé au début des épidémies. « Vous avez
quelqu’un qui se reproduit avec un taux appelé R zéro (R0), qui devient le
nombre moyen de personnes infectées par un malade dans le cas des épidémies,
détaille Jean-Stéphane Dhersin. Ce R0 est actuellement d’environ 2,5
pour Covid-19. »
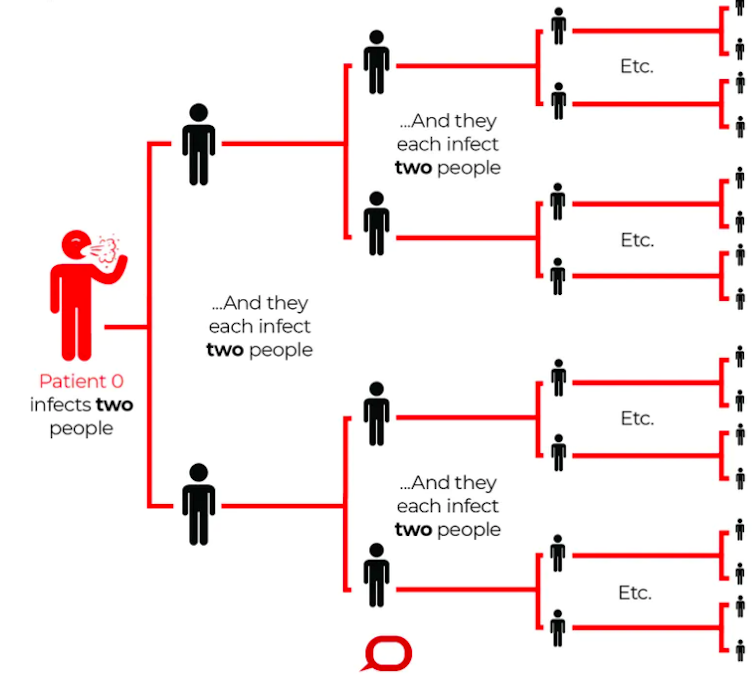
Quand R0
tombe en dessous de 1, l’épidémie recule. C’est d’ailleurs ce qu’il se passe à
présent en Chine. Ce R0 peut être diminué en renforçant l’immunité collective
par le biais de la vaccination. Cette option n’est malheureusement toujours pas
disponible pour Covid-19. À rebours, R0 permet de calculer le taux d’immunité
collective nécessaire pour que l’épidémie régresse. « Avec le R0 actuel
de 2,5, il faudrait que 60 % de la population soit touchée, déplore
Jean-Stéphane Dhersin. C’est beaucoup trop. » Un R0 faible
signifie également un pic de cas moins important, plus tardif et étalé. Jean-Stéphane Dhersin
cite en exemple l’épidémie de SRAS de 2003. « Les malades
présentaient des symptômes seulement deux ou trois jours après l’infection, ils
ont donc pu être rapidement isolés. Le R0 est ainsi passé de 3 à moins
de 1. L’épidémie s’est arrêtée et, une fois tous les cas retirés, n’a pas
pu reprendre. »
Les toutes
premières actions pour faire baisser le R0, calquées sur celles du SRAS, se
sont ainsi révélées insuffisantes. « L’objectif est de faire baisser R0,
pour arrêter l’épidémie ou a minima ne pas engorger le système de santé. »
Jean-Stéphane Dhersin fait cependant remarquer que la décision d’appliquer
une stratégie ou une autre n’est pas uniquement scientifique. Les mesures ont
un coût, social ou économique, qui peut pousser les décideurs à introduire
graduellement les différentes mesures.
En ces
temps d’inquiétude et de fake news, les citoyens cherchent naturellement
à se renseigner sur tous les modèles existants. Ceux-ci ne sont cependant pas
forcément rédigés à destination du grand public. « L’important est de
bien prendre en compte la sensibilité aux hypothèses des modèles, conseille
Samuel Alizon. Les modèles sont toujours issus d’une simplification de
la réalité, parfois sur plusieurs aspects à la fois. Ensuite, il faut prêter
attention aux intervalles de confiance et ne pas se concentrer uniquement sur
la médiane. » En effet, si on lit que 2 % des personnes infectées
vont décéder, mais que la marge d’erreur est même de seulement un point de
pourcentage, le nombre final varie en réalité... entre moitié moins et moitié
plus.
Notes
- 1. Unité CNRS/Université Le Havre Normandie/Université Caen Normandie/Université Rouen Normandie.
- 2. Unité CNRS/IRD/Université de Montpellier.
- 3. Unité CNRS/Université Sorbonne Paris Nord.
Aucun commentaire:
Enregistrer un commentaire