Décidément, le Covid 19 aura pris et continue à prendre tout le monde de court, y compris les féru(e)s des mathématiques des épidémies. Contrairement à ce que d’aucuns ont déclaré ou pensé sans le dire, ce ne sont pas seulement les caractéristiques du virus qui ont posé problèmes. Le comportement des individus aura été et reste déterminant dans l’évolution de la pandémie, en attendant un remède et, plus tard, un vaccin homologué.
Laurent Dumas est Professeur des Universités, Laboratoire de Mathématiques de Versailles, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Lors de son allocution du 28 avril préparant le déconfinement du 11 mai 2020, Édouard Philippe a mentionné certains indicateurs issus de modélisations mathématiques montrant l’intérêt du confinement et la situation à prévoir au 11 mai. On peut citer les extraits suivants de son allocution :
· « Les modèles épidémiologiques prévoient entre 1000 et 3000 cas nouveaux chaque jour à partir du 11 mai »
· « Le confinement aura permis d’éviter au moins 62 000 décès sur un mois »
Peut-on avoir confiance en ces chiffres en se basant sur les bilans nationaux donnés chaque jour par Santé publique France et reproduits ci-dessous ?
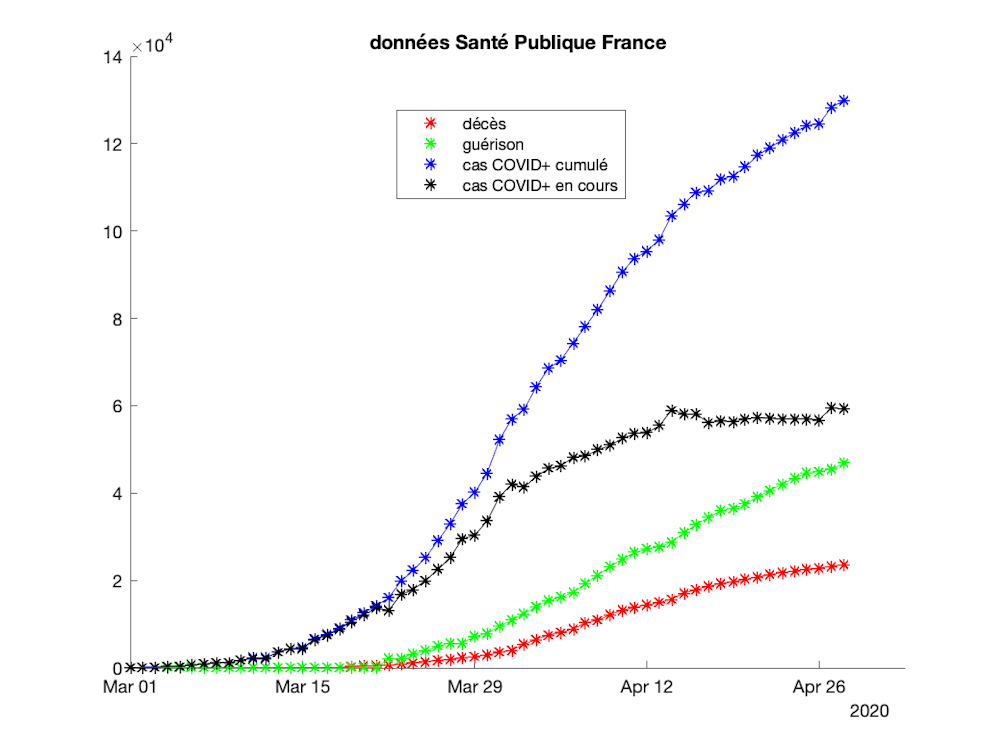{kind=link}

France - Figure 1 : Données Santé publique France du 01 Mars au 28 avril
De manière simple, la modélisation mathématique est un outil permettant de mieux comprendre la réalité qui nous entoure afin d’être capable de la prédire. Elle consiste à traduire en équations un phénomène observé, qu’il soit physique, biologique ou économique. Ces équations s’écrivent souvent sous la forme d’équations différentielles ou aux dérivées partielles, dont les solutions représentent l’évolution dans le temps et/ou dans l’espace du phénomène que l’on cherche à étudier.
L’épidémie actuelle du COVID est donc une « aubaine » sur laquelle les modélisateurs se sont rapidement penchés : il s’agit en effet d’un phénomène à la fois bien connu en épidémiologie mais aussi nouveau par son ampleur et par les moyens déployés pour l’endiguer. En outre, les données quotidiennes recueillies sont une ressource rare et précieuse dans ce domaine pour alimenter et valider les modèles utilisés.
Posons les bases mathématiques
Les modèles mathématiques en épidémiologie ont été explorés depuis très longtemps et leur forme actuelle date de plusieurs dizaines d’années. Cette expression simple vient du fait que le virus se propage uniquement à travers le contact entre une personne infectée et une personne saine. De plus, il est souvent possible d’estimer la durée de contagiosité pour une pathologie donnée (comme c’est le cas pour le COVID, entre 12 et 20 jours).


Les premiers modèles apparus et toujours utilisés actuellement, consistent à classer la population en trois catégories : les personnes saines non immunisées à l’instant t (en proportion S(t)), les personnes infectées (en proportion I(t)) et les personnes en rémission (en proportion R(t)), de telle sorte que S+I+R =1 à chaque instant, et à traduire les observations précédentes en un système d’équations différentielles (appelé modèle SIR) :
S’(t)=-a I(t)S(t)
I’(t)= a I(t)S(t)- b I(t)
R’(t)= b I(t)
Le paramètre a s’appelle le taux de transmission et b le taux de rémission. Il est alors intéressant de définir une quantité appelée R0 telle que : R0= S(0)*a/b et d’observer que si R0>1 l’épidémie va se propager alors que si R0<1, elle va se résorber. Ce nombre peut aussi être vu comme le nombre de personnes qu’une personne infectée va contaminer et ainsi être facilement interprété dans le langage commun.
Explication en vidéo des modèles mathématiques pour le Covid-19 (voir le site web).
Suivant les cas étudiés, ce modèle a été complexifié, soit en rajoutant des nouvelles catégories de population (comme les personnes exposées et non encore infectées), soit de nouveaux termes d’échange ou une composante spatiale prenant en compte les mouvements des individus.
Il est aussi intéressant de constater qu’une approche probabiliste à l’échelle de l’individu conduit après passage à la limite vers un modèle de type SIR.
Un modèle simple pour décrire la propagation de Covid-19 ?
Reste quand même à voir comment se comporte ce modèle simple face à l’épidémie du Covid-19 qui ne ressemble à aucune autre et surtout comment « réagit » le modèle par rapport aux mesures de santé publique comme le confinement.
Au cours de la première phase de l’épidémie (eu Europe, disons de fin février à mi-mars), on s’aperçoit que le modèle SIR reproduit très bien les différents démarrages de l’épidémie dans tous les pays. Ce démarrage, de nature exponentielle a conduit à estimer la valeur du R0 autour de 2,5 à 3 avant les premières mesures de santé publique. En outre, les déplacements de populations ayant déjà fortement diminué, la composante spatiale peut être négligée et il est alors possible d’observer le début de la croissance dans un pays ou dans une région donnée de manière homogène.
À partir du moment où l’épidémie était lancée, deux stratégies de santé publique ont été évoquées :
- L’immunité collective, consistant à laisser se propager la maladie (et aussi le modèle initial) jusqu’à faire décroître mécaniquement le R0 en dessous de 1. Autrement dit, l’épidémie serait enrayée lorsque S(0)=1/3 soit lorsque 2/3 de la population serait atteinte… Hypothèse vite abandonnée, un peu plus tardivement au Royaume-Uni, au vu de la vague de malades graves induite dépassant très largement les capacités hospitalières.
- La seconde stratégie a consisté à prendre des mesures très fortes limitant les risques de transmission. En d’autres termes, ce n’est pas S(0) qui vient à bout de l’épidémie mais la décroissance de a au détriment cependant de l’immunité collective.
C’est alors qu’entre le 10 et le 20 mars une série de mesures (distanciation sociale, fermeture des écoles, confinement général) ont été prises en Europe dans le but d’« écraser la courbe »… Qu’est-il advenu alors des modélisations et du modèle SIR ? Disons qu’il a bien tenu le choc mais qu’il a fallu l’adapter.
En étudiant l’évolution du taux de transmission entre mi-mars et fin mars, il est apparu dans chaque pays européen le même comportement pour le taux de transmission : celui-ci a effectivement pris une nature fortement décroissante en fonction du temps.
En reprenant donc le modèle SIR mais avec un taux variable a(t), il a été observé de manière très reproductible dans chaque pays que ce taux pouvait être considéré comme décroissant exponentiellement :
a (t)= c exp(-d t)
Ceci s’explique fort bien au niveau d’un individu : le confinement a consisté à réduire en moyenne par une fraction constante chaque semaine le nombre de contacts avec les personnes infectées… ce sont ici les données qui l’indiquent et non une information que nous fournissons au modèle.
On pouvait aussi se demander ce qu’il adviendrait du taux de rémission b, fortement relié pour sa part aux caractéristiques de l’épidémie. En prenant un taux de rémission non plus constant mais variable, b(t), on observe à l’inverse du taux de transmission que celui-ci demeure très stable (il croit très légèrement) depuis le début du confinement avec une valeur moyenne inchangée d’un pays à l’autre aux alentours de 1/13. Autrement dit, le confinement a eu un fort effet sur la réduction des relations entre les personnes saines et les personnes infectées tandis que le traitement de ces dernières ne connaissait pas d’amélioration.
Il ne reste plus alors qu’à faire apprendre au modèle les données collectées pour qu’il estime les valeurs de c et d au jour courant. En choisissant pour cela une fenêtre de 10 jours dans le passé, on aboutit alors à une modélisation mathématique ne comprenant aucun paramètre fixé arbitrairement mais seulement des paramètres appris avec les données.
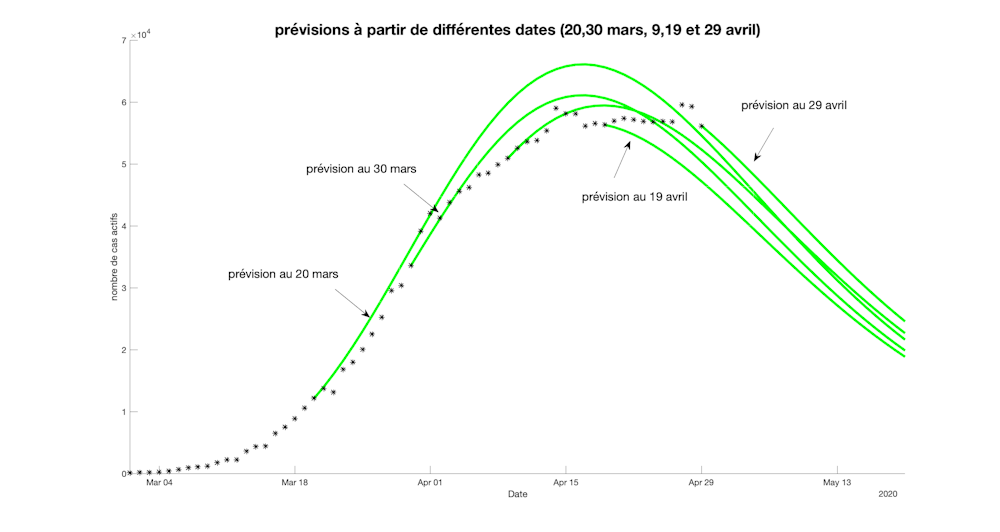{kind=link}

Figure 2 : évolution du nombre de cas actifs en France à partir des données collectées jusqu’à différentes dates : 20 mars, 30 mars, 9, 19 et 29 avril.
Avec le recul acquis depuis le début de l’épidémie, il est possible à présent de tester la validité de ce modèle SIR « auto-apprenant » pendant la période de confinement. Les figures 2, 3 et 4 confirment la pertinence des choix effectués en comparant les prévisions réalisées en France à différentes dates pendant le confinement (20 mars, 30 mars, 9, 19 et 29 avril) et en observant leur très bonne coïncidence. Il est important de noter que la stratégie de tests consistant à ne dépister que les cas nécessitant une éventuelle hospitalisation est restée inchangée jusqu’à ce jour. Le nombre de cas réels est bien au-delà de cette valeur mais le modèle a simplement ici pour objectif de prédire le nombre de formes graves.
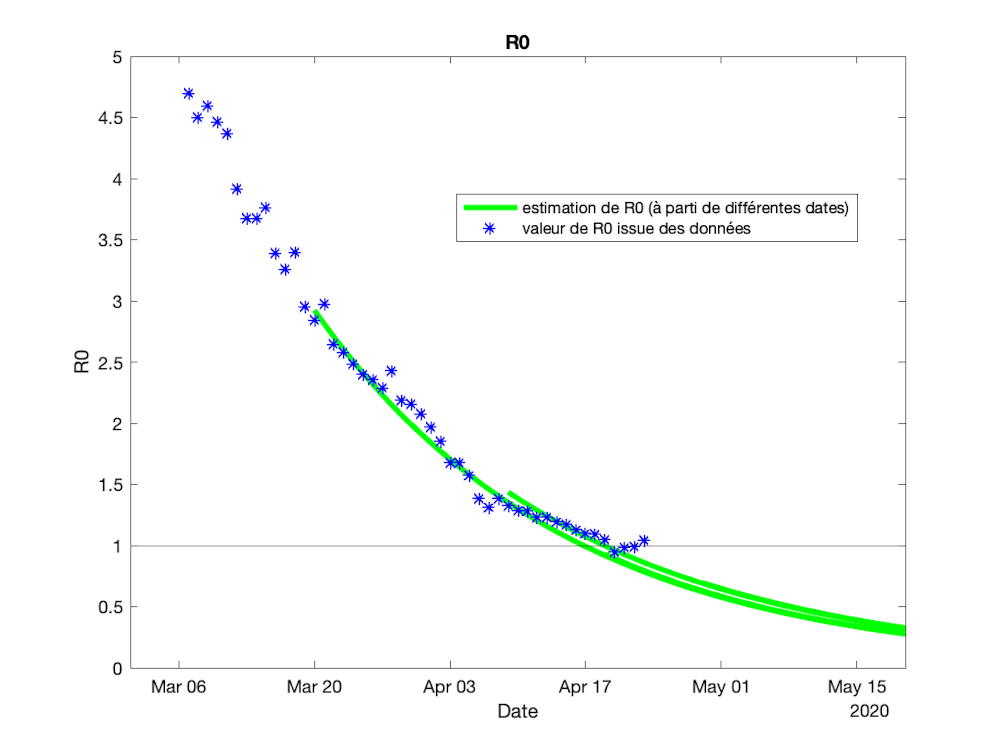{kind=link}

Figure 3. Valeur du taux R0 (issue des données) et estimation de ce taux à partir des données collectées jusqu’à différentes dates : 20 mars, 30 mars, 9, 19 et 29 avril
Cette approche semble ainsi apte à prédire certains aspects de l’épidémie, par exemple le moment du « pic » de contamination, c’est-à-dire ici le moment où le taux de reproduction R0 passe en dessous de la valeur critique égale à 1 (voir figure 3) mais aussi d’autres données comme la variation quotidienne de nouveaux cas ou leur nombre (voir figure 4).
{kind=link}


Figure 4 : évolution de la variation de cas actifs (g.) et du nombre de nouveaux cas (d.) à partir des données collectées jusqu’à différentes dates : 20 mars, 30 mars, 9, 19 et 29 avril (à noter qu’une erreur de remontée entre le 28 et le 29 avril fait apparaître un nombre de nouveaux cas non réaliste au 29 avril).
Les projections du gouvernement sont-elles compatibles avec ce modèle ?
Ainsi la première affirmation d’Édouard Philippe concernant le nombre de nouveaux cas quotidiens à prévoir le 11 mai (entre 1 000 et 3 000) paraît tout à fait raisonnable (voir Figure 4, droite).
Concernant le nombre avancé de 62 000 morts évitées au minimum, il est par contre beaucoup plus difficile d’être catégorique avec une valeur aussi précise.
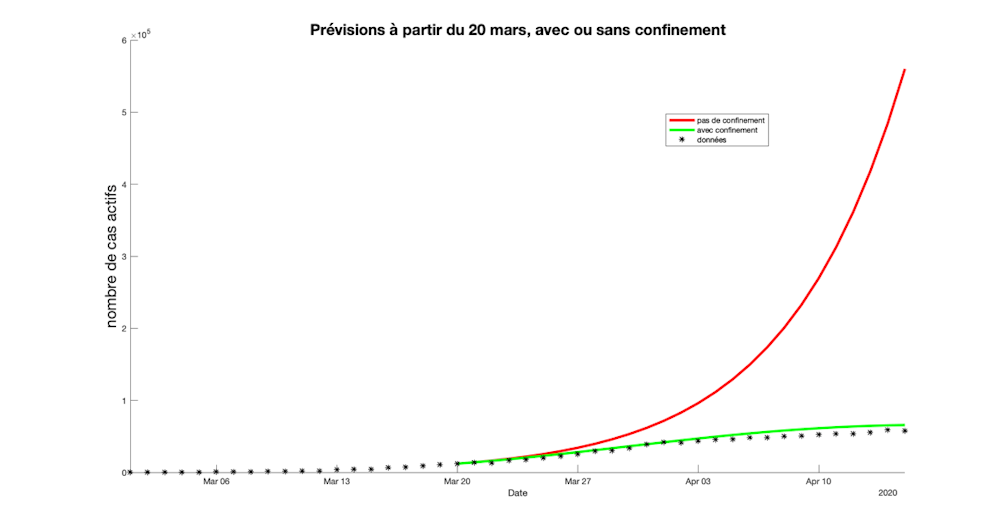{kind=link}

Figure 5 : comparaison du nombre de cas au 15 avril pour un scénario avec ou sans confinement.
Si on essaie cependant de modéliser un scénario sans confinement, on peut par exemple regarder ce qu’il se passe en laissant le taux de transmission constant et égal à sa valeur estimée au 20 mars, soit quelques jours après la mise en place du confinement. La figure 5 montre que le nombre de cas actifs aurait alors été multiplié par 10 un mois plus tard. Le système de santé aurait été totalement saturé et on peut effectivement imaginer qu’avec 600 000 personnes nécessitant une potentielle hospitalisation au lieu de 60 000, la situation sanitaire aurait été dramatique.
A noter que toutes ces observations ont également pu être vérifiées dans l’ensemble des pays européens ayant adopté à la même période un confinement de même nature plus ou moins strict.
Un risque de deuxième vague ?
Après le déconfinement, l’horizon se bouche et plusieurs inconnues demeurent : combien de personnes seront immunisées après la première vague ? Si ce nombre ne dépasse pas 10 %, c’est-à-dire que S(0)=9/10, il faudra s’armer de patience et craindre des répliques nombreuses si les habitudes se relâchent. D’autre part, quelles seront les nouvelles habitudes de chacun dans une phase de déconfinement totalement inédite ? Comme pour la période de confinement, il faudra attendre quelques jours avant que le modèle nous livre lui-même l’information.
Rien ne dit que le fameux R0 poursuivra sa décroissance après le 11 mai : le confinement aura fait passer sa valeur de 3 à 0,4 environ (voir figure 3) au prix d’un effort collectif immense, le déconfinement aura pour mission de le maintenir plus petit que 1 pour que l’épidémie ne redémarre pas.
Pour finir, on peut se demander ce qu’il en est dans d’autres pays non européens : en observant l’exemple de la Corée du Sud, il est intéressant de constater que l’approche précédente ne donne pas de bons résultats sur ce pays. Ce n’est pas un échec du modèle en réalité mais plutôt la traduction que les habitudes des populations et les moyens de combattre l’épidémie sont très différents.
Cela montre aussi que dans ce domaine, ce ne sont pas les mathématiques qui ont le dernier mot mais bien les individus.
Aucun commentaire:
Enregistrer un commentaire